Am Anfang lohnt es sich, den Blick kurz zur Ruhe kommen zu lassen. Samstag nutze ich gern, um inspirierende Fotos zusammenzutragen. Werde dabei nicht ungeduldig; eine sorgfältige Auswahl schärft das Auge. Ich sortiere Motive nach Licht, Form und Stimmung. Nicht jedes Bild taugt zum Vorbild – wähle bewusst. Vorbeikommen kann außerdem jederzeit eine spontane Idee, die alles umwirft.
Bevor du überhaupt zum Bleistift greifst, lohnt es sich, eine vielfältige Sammlung von Bildern anzulegen. Suche nach Fotos, die die ganze Pflanze oder sogar ein Beet zeigen, ebenso nach Nahaufnahmen, die den Moment des Aufblühens oder die seidige Oberfläche eines Blütenblatts einfangen. Je mehr Varianten dein Auge sieht, desto tiefer wird dein Verständnis des Motivs.
Vertiefe anschließend dein Wissen: Ein Wikipedia-Artikel oder ein botanischer Führer genügt meist, um die typische Anordnung der Blüten, die Zahl der Blätter und mögliche Farbvariationen kennenzulernen. Diese Recherche verhindert Proportionsfehler und schenkt vor allem das Selbstvertrauen, die Pflanze interpretierend statt mechanisch zu kopieren. Um das Gelernte festzuhalten, gestalte ein Moodboard – analog oder digital. Indem du deine Lieblingsfotos dort sammelst, entsteht eine schnelle Referenz, die dich während des ganzen Prozesses inspiriert.
Die Grundformen skizzieren
Es hilft, mit einer klaren Struktur zu starten. Ist die Mittelachse gesetzt, entsteht sofort Ordnung. Noch bevor Details auftauchen, erkennst du die Proportionen. Zu viele Linien am Anfang verwirren nur. Früh erprobst du leichte Striche, die sich später gut anpassen lassen. Für stabile Formen genügt ein lockerer Griff. Ein gleichmäßiger Druck vermeidet harte Kanten. Wiedersehen wirst du diese ersten Markierungen erst, wenn die Komposition steht.
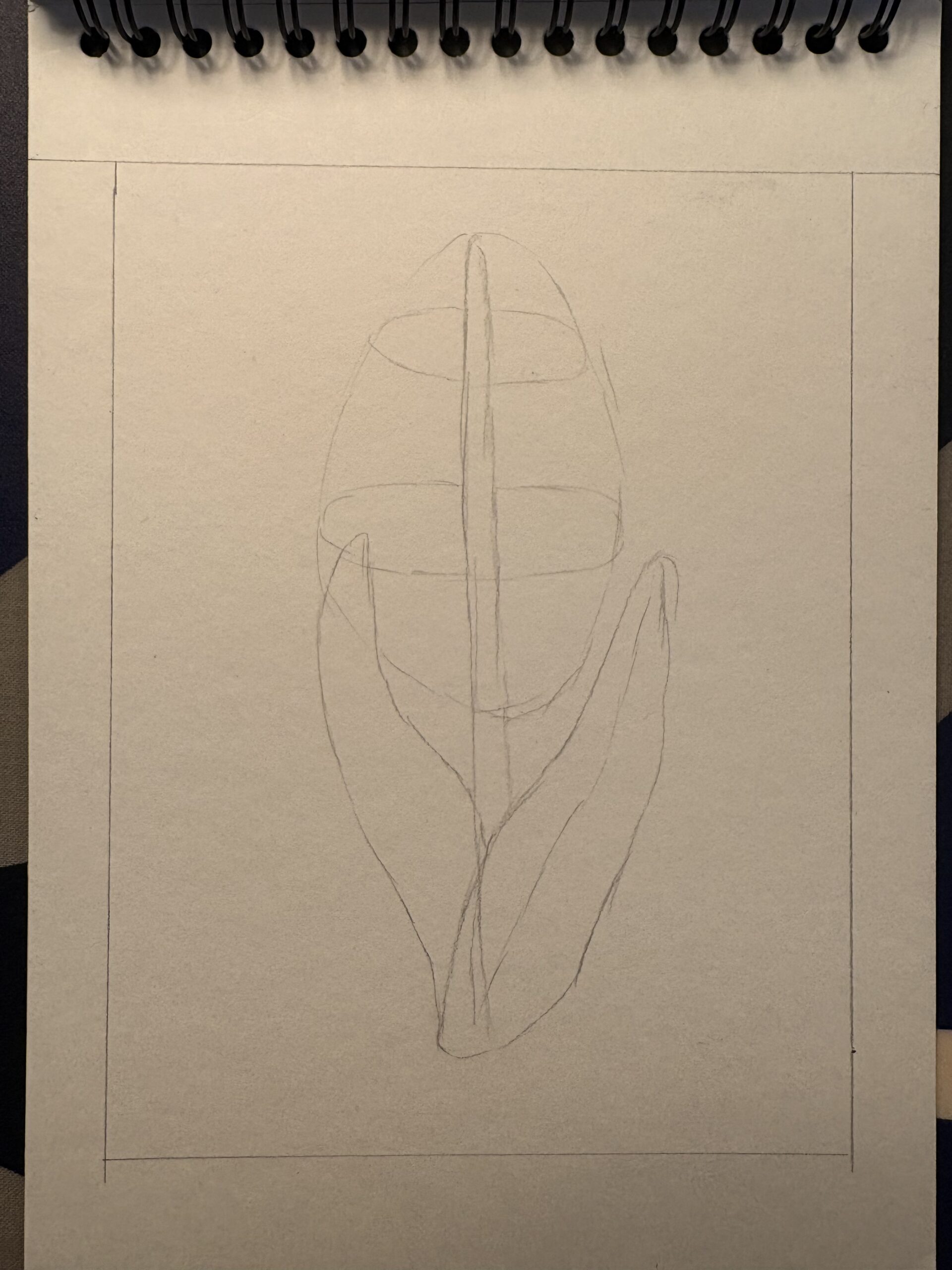
Grundformen skizzieren
Sobald das Referenzmaterial bereitliegt, setze den ersten Graphitstrich aufs Papier. Zeichne zunächst die vertikale Achse des Stängels – sie bildet die Wirbelsäule deiner Komposition. Skizziere um diese Achse einen hauchzarten Zylinder; darin werden später die Blüten Platz finden. Am Fuß der Pflanze legst du zwei lange, bandförmige Blätter an, bloße Silhouetten, die die Zeichnung erden; weitere Blätter lassen sich bei Bedarf ergänzen. Diese Phase bleibt bewusst grob: Es geht darum, die großen Massen zu positionieren, nicht sofort um Präzision.
Die Blüten Schritt für Schritt aufbauen
Diese Etappe dreht sich um einzelne Blüten. Entscheidung für ihren Rhythmus triffst du schon jetzt. Habe deshalb den Aufbau der sechs Blütenblätter präsent. Ich drehe das Papier leicht, um die Spirale zu prüfen. Aus kurzen Notizen entsteht oft ein konkreteres Bild im Kopf, noch bevor der Stift es zeigt. Respekt vor dem natürlichen Schwung bewahrst du, indem du locker bleibst. Vor jeder neuen Blüte kontrolliere die Gesamtsilhouette. Dir fällt dann auf, wie organisch sich das Muster fortsetzt.
Richte deine Aufmerksamkeit nun auf eine einzige Blüte. Eine Hyazinthe besitzt fast immer sechs Blütenblätter: drei sich gegenüberliegende Paare, die um ein winziges Zentrum kreisen. Um dir diese Struktur einzuprägen, setze zunächst sechs federleichte Striche in Sternform, so zart, dass sie später spurlos wegradiert werden können. Umschließe jedes Segment dann mit dem weichen Umriss eines Blütenblatts.
Wiederhole das Ganze einige Male, bis die Hand den Rhythmus verinnerlicht hat. Sobald die Bewegung vertraut ist, neige die Kronen, platziere einzelne Blüten im Profil oder Dreiviertel-Winkel, damit die natürliche Drehung um den Zylinder erhalten bleibt. Nach kurzer Zeit entsteht ein spiraliges Muster, das die Gesamtsilhouette des Blütenstands deutlich macht.
Blüten und Details aufbauen
Den Blütenstand füllen und verfeinern
Und sobald der Raum dicht wirkt, wechselst du zu den Blättern. Uns helfen dabei dezente Schraffuren, die Volumen andeuten. Getroffen werden Lichtakzente erst ganz zum Schluss.
Arbeite weiter, bis der für die Blüten reservierte Raum dicht und lebendig wirkt. Kehre dann zu den Blättern zurück: Füge ein oder zwei hinzu, betone die Mittelrippe und spiele mit Halbtönen, um ihre fleischige Textur hervorzuheben. Auf dem Stängel setzt du gezielt Lichtakzente; zwischen den Blütenblättern vertiefst du unaufdringliche, aber entschlossene Schatten. Die allmählich aufgebauten Hell-Dunkel-Werte verleihen Volumen, ohne die Frische der ersten Skizze zu ersticken.
Ich muss auch selbst noch weiter daran arbeiten, deshalb habe ich noch keine weiteren Bilder von meiner Zeichnung. Ich hoffe, dass ich sie in den nächsten Tagen hinzufügen kann.
Zeichnen, um zu empfinden
Jede gestalterische Entscheidung – ob du frisch erblühte oder verwelkte Blüten zeichnest, die Pflanze im Topf oder im Gartenboden zeigst, Tau, Regen oder Reif einfügst – ist eine Gelegenheit, eine innere Stimmung auszudrücken. Frage dich: Fühle ich mich zur Lebenskraft eines frühlingshaften Bouquets hingezogen oder zur sanften Melancholie eines verdorrten Stängels? Indem du diese Resonanzen wahrnimmst, übst du Achtsamkeit: Du beobachtest deine Emotionen, nimmst sie ohne Urteil an und verwandelst sie in Linien, Schatten und Nuancen.
Zeichnen als Teil einer emotionalen Selbstfürsorge
Das Zeichnen ist nur eine von vielen Türen zur Gegenwärtigkeit. Ein Spaziergang, ein Musikstück oder einige Yoga-Positionen können dieselbe Funktion übernehmen. Ein persönliches, flexibles „Achtsamkeits-Set“ aus verschiedenen Praktiken zu gestalten hilft oft, kontrastreiche Tage zu meistern: An einem Nachmittag beruhigt der Skizzenblock, am nächsten vervollständigt der Gang durchs Viertel den Prozess. Entscheidend ist das Lauschen auf die Bedürfnisse des Augenblicks und die Freiheit, das Medium zu wechseln, sobald der innere Impuls es verlangt.
Persönlich entdecke ich Aktivitäten wie Zeichnen, Wandern, Radfahren, Beobachten oder Schreiben wieder. Ich schreibe gerne kurze Texte oder Gedichte, oder spiele einfach mit Worten Diesmal haben nur bestimmte Sätze eine andere Bedeutung
Fazit
Ich fasse zum Abschluss die Essenz zusammen. Werde beim Zeichnen bewusst langsamer als gewohnt. Euch wird auffallen, wie sich mit jedem Strich das Bewusstsein klärt. Sehr schnell verschwindet der Drang nach Perfektion. Vermissen wirst du nichts, wenn du ganz im Augenblick zeichnest.
Eine Hyazinthe zu zeichnen ist folglich nicht bloß eine botanische Beobachtungsübung; es ist eine Einladung, das Tempo zu drosseln, bewusst zu atmen und sich selbst wie in einem weichen Spiegel zu betrachten. Ganz gleich, ob du Anfänger*in oder bereits erfahren bist, lass deine Stifte dem Atem folgen; Blütenblatt für Blütenblatt entsteht sowohl eine grafische Blume als auch ein feineres Bewusstsein für den gegenwärtigen Moment. Eine inspirierende Entdeckungsreise wünsche ich allen Zeichnenden.
I am at a new crossroad in my life where I am aspiring to take a new direction. I am still passionate and eager to learn about new technologies, programming, etc. But I have other interests, some old some new, which I want to explore and maybe share.
I have started to learn about calligraphy and even if I am at the very beginning and just exercising, it is reviving some older and buried activities such as writing. I usually write in French, my mother tongue. So there might be more French posts in the future here.
I am not yet sure if I will write regularly. And perhaps, I don’t want to publish anything. It’s more for myself than for anyone.
As for the thoughts, I am appalled by the current situations where intolerance, racism, stupidity and egoism are growing. I am for more diversity in our society, culture, workplace and life; we don’t have a planet B, we need to protect it; I want more tolerance, the fact that we are all so different, think different is just amazing and interesting, we should be opened to others whatever their looks, beliefs or choices. I stopped using Twitter when it was acquired by this mad man and after the election in the US last year, I deleted my account. I have been demonstrating last year and this year for more diversity and tolerance, and will continue doing this. I am passing on these values to my kids.
There is a subject which seems to be completely abstruse to many users of containers on Linux, it is about sharing data between a host and a container or between containers.
I do think that solving this problem is not much different than it is without containers on Linux and on Unix. From my perspective, there is no much difference between managing file permissions with or without containers, the big change for me is the introduction of namespaces, especially the user namespaces.
So what is exactly the problem? And where does it come from?
The problem is that when running a process within a container, that process will run with a certain user and group ID (respectively UID and GID) and that those IDs might differ from the ones of the caller (the user creating and running the container), this might not be obvious. This is especially true with container technologies like Docker which by default will run the process within the container as root (unless overridden in the Dockerfile or command line) when any user with write access to the Docker socket can create such container. So you have by default a discrepancy for the UID and GID between the caller – probably a standard user – and a random Docker container.
In traditional Unix / Linux, this is “normal” or “expected” behaviour. You usually cannot run a process as root from your normal user unless you use sudo or a setuid program, so usually you do not have the problem that a program you launch might have different UID/GID than your own user. And when you use a program with sudo you understand that this might become a problem, so if you use sudo to run `tcpdump -w net-trace.pcap` you know the file net-trace.pcap will be owned by root and that you might not be able to access or delete it. This reflex needs to apply to running a container as well.
When you have done Unix/Linux development most of your career – and that you have adopted the principle of least privileges … I still know of few people only using the root account – you are used to create application that will run in the background (as a service) under a dedicated user and for which you need to handle the permissions for the data this application might need to use. So introducing containers (without user namespaces) should not bring any surprise here, it is part of the expectations. But you will see later that you can still be bitten by some edge cases from the container implementation.
So, let us see how to fix this problem of User/Group ID and file permissions. Note that the solution would be similar if you would use containers or not, and applies to all container implementations (e.g. LXC, Docker, etc.). Then, for everyone, we will see how to handle file permissions when using user namespaces (hint, the principles are the same, but it requires a few extra steps to understand what will be the effective UID/GID). Finally, in the case of Docker, we will see a few edge cases where you can still get off guard with respect to file permissions and volume declaration inside a Dockerfile.
There is a new feature coming to Firefox which was discretely introduced in Firefox 50 Nightly and is getting improved with follow up releases. It is called Containers and is part of the of the Contextual Identity Project.
In short each container – or context – is a “colour-coded” tab with a dedicated environment to help one separate his/her online activities. So you can have tabs in a particular context and others in another context.
This increases privacy, so sites cannot spy on you outside of the context you use them. It allows separation of concerns, so you can use a website (e.g. GitHub) for work and personal use inside the same browser but with each a different account. It increases security so if you access your bank in a dedicated context, it would be harder to perform some attacks (e.g. cross-site scripting) to access your bank data.
To activate it you can go to about:config page and then set to true the entry privacy.userContext.enabled, you get the vanilla experience, still a bit rough in Firefox 60 and 61, already quite improved in Firefox 62 Developer Edition. A recommended alternative is to use Mozilla’s Addon called Firefox Multi-Account Containers which provide a nice icon and a walk-through. It works at least on Firefox for Linux, macOS and Windows.
This is how it looks like on Ubuntu (I’m using the default Dark theme). You can see that my Gmail is opened in a blue-coloured container, I have GitHub in a purple, a shopping site in a pink “Shopping” and finally a news site in no specific container. I could open another tab to my Grafana site in the same purple-coloured container as GitHub, and I would then be able to use GitHub OAuth to login to Grafana. If I would open Grafana in another or no container, I would not be able to use GitHub OAuth without re-authenticating myself to GitHub in this new context.
Firefox Containers illustration
So I’m really looking forward to improvements on Firefox Container.
Today I activate a new feature at work which provides the Container Registry feature on our GitLab instance.
However not all projects are requiring this feature, actually at the moment just a few. Therefore we wanted this option to be disabled by defaults and to the responsibility of the project leaders to activate or not when needed.
GitLab offers to disable the Container registryfeature for new projects only. What I wanted was to do that for existing projects. This needs to be done directly on the database, so back it up before doing this, and try it on a non-production environment first. Note that this was tested on GitLab 8.17.3 using PostreSQL 9.6, with other releases this could be different. In addition, the following is provided as is without any warranty, it worked for me, it might not for you and I’m in no way responsible if you mess your database.
Now that you have done your backup, to perform the changes on the database, you need to login as the `gitlab-psql` user:
When using Docker:
$ docker exec -it --user=gitlab-psql gitlab bash
When using omnibus package:
$ su - gitlab-psql
The following applies for both Docker and Omnibus installation once logged in:
Run ntpd to provide time to your local network (Docker), I will talk about the pros and cons of running that on a Raspberry Pi: published
Run dnsmasq to provide a DHCP and DNS resolver on your local network (Docker): draft-only
This website is now using TLS so that the URL has changed to HTTPS. The certificate authority is Let’s Encrypt which my hosting provider is offering easily. I will show how easy it can be to setup HTTPS on WordPress: draft-only
I have a few more unfinished articles which might still take some time to complete, topics are ranging from: LXC advance usage and tips&tricks, LXD first usage, Linux SSH key management, SSD caching on Linux, FreeBSD/Arch Linux on Raspberry Pi 2.
Last but not least, I ought to announce why I’ve been so busy in the past months (and years). I will give some hints soon.
As I’m trying to prototype some sensors which I will then use around my home to monitor events and perhaps also react on them, I’ve been a bit more looking at the Internet of Things (aka IoT) trend. So here is my opinion on IoT in regards to personal home automation.
And to start franckly, I think the use of IoT for home automation is idiotic. It is my view that current companies in this field understood IoT as being online, in the cloud, whereas I thought it was about to be based on network standards (such as those used on the internet) for improved interoperability. Why is it needed to make it “internet” connected (collected)? It really does not need to be on the internet, IoT just needs the local network access and standard communication stack!
I think the monitoring elements, the storage of this data, the analysis and control systems, and the actuators should all be local, in house. If an actuator needs data from the Internet or in the end calling an internet service it’s still possible even if it stays local. There is absolutely no advantage to have all this in a “cloud”, this is only to the benefits of ad agency and other agencies which can use your data to better “monitor” you!
And having an IoT brings many challenges: data transmission, congestion, storage, latency, security, privacy, etc. some of those are mentioned in this article I found on Twitter today. But this article is also oriented towards other usage for IoT than in the house. (Note that if you’re used to build M&C – Monitoring and Control – systems, you will not be surprised by this article content, these are classical challenges in M&C domain).
From my perspective and when used within a house, my decentralized approach to IoT (without cloud or external internet services) is not subject (to the same extent) to most of the challenges presented in this article.
I also think that data retention for a house is really limited (e.g. only the latest status for a window/door open state sensor; maybe up to a week/month of data from a temperature sensor; etc.) so storage of data is not challenging.
Latency is also not such a problem. Only few actuators in a home would require immediate response (e.g. so called “smart lock”). For other sensors the reporting of new data could be cyclic (with long update cycles such as once every 15 minutes) or on change (with big thresholds) because latency is of such lower priority.
I therefore think a device as simple as a Raspberry Pi 2 is perfectly suited to be the core element of a Home Automation system. It has enough processing power, storage capacity, interfaces capabilities to be the host of all the gathering of monitored data, their processing and analysis, and of all actuators. And it can easily use internet services (if need be) thanks to its network interface.
If one day I find the need to have access to my home automation system, it will be simply done from my mobile via VPN or router configuration.
As a conclusion you can find consolidated here my opinion regarding IoT and Home Automation:
On premise: the data should not leave the house, processing and controlling should be done at home;
No Cloud: this is the corollary to my previous point. The data belong to us and shall be kept private. Pushing them to the cloud add complexity, risks with no benefits;
Open standards: communication and interoperability are paramount for the success of IoT. Adding a new IoT device should be easy; and
Short data lifespan: no need to keep tracks of IoT data for long periods. Most of it is interesting only the moment it changes and then can be forgotten.
I don’t have much time to explore more my Raspberry Pi or other technical stuff lately, because I have lots of interesting (and also demanding) stuff to do in my non-cyber life (the real one)!
But I always have an eye on what’s happening there and when I saw availability of the .space domain, I hesitated a few months before I could not resist it any longer.
You can now visit my site using berthon.space! You will land for the moment on the same page. I have time now to think how I will personalise this domain.
Comments are the feature least used on this blog. In addition, they could pose a security risk by allowing anonymous user entries (see WordPress 4.2 Stored XSS). I am therefore closing them and I am not sure I will reopen them in the future.
I plan to move this blog to a static blog engine (such as Octopress but I haven’t selected one yet). Such engine – as far as I know – do not support comments and I don’t want to rely on 3rd party products such as disqus for obvious privacy reasons which I’m not going to details now.
There are several ways to continue the discussion with me. Social “media” are one, and eventhough I’m not really active there, I’m monitoring them. I will think of other ways to provide discussions and update this post.
Today I took the decision to block all comments on Magical World.
Spammers are currently flooding the blog with spam which are filling up our backend database (it is a small and cheap hosting service). Although all spam are captured by our spam filter, we end up with our hosting service provider blocking SQL insert and update statements. It basically freezes our website.
In the near future I will evaluate a better solution and restore comments. But for the time being, feedback can be provided to us via the contact us page.







 As I’m trying to prototype some sensors which I will then use around my home to monitor events and perhaps also react on them, I’ve been a bit more looking at the
As I’m trying to prototype some sensors which I will then use around my home to monitor events and perhaps also react on them, I’ve been a bit more looking at the  I therefore think a device as simple as a Raspberry Pi 2 is perfectly suited to be the core element of a Home Automation system. It has enough processing power, storage capacity, interfaces capabilities to be the host of all the gathering of monitored data, their processing and analysis, and of all actuators. And it can easily use internet services (if need be) thanks to its network interface.
I therefore think a device as simple as a Raspberry Pi 2 is perfectly suited to be the core element of a Home Automation system. It has enough processing power, storage capacity, interfaces capabilities to be the host of all the gathering of monitored data, their processing and analysis, and of all actuators. And it can easily use internet services (if need be) thanks to its network interface.